The Architectural Saga of Kubernetes
An interactive guide to understanding the evolution, architecture, and operational genius of Kubernetes, the operating system for the cloud.
From Digital Blacksmiths to Cloud Cities: The Genesis of Kubernetes
In the grand chronicle of software, our story begins not with clouds and containers, but with iron and sweat. In the primordial era of computing—the age of Bare Metal—servers were treated as unique, cherished pets. This technological reality was intertwined with the dominant software development methodology of the time: Waterfall. Just as Waterfall projects flowed sequentially through rigid phases over months or years, so too was the application a single, indivisible monolith. A change in one small part required rebuilding and redeploying the entire system—a high-stakes, low-frequency event. Scaling was a matter of brute force and budget, and the artisanal approach to both software and servers was slow, inefficient, and profoundly fragile.
The first great migration was sparked by the invention of the hypervisor, giving rise to the Age of Virtualization. This technological shift coincided with the rise of Agile development. Teams sought to break free from Waterfall's rigidity, embracing shorter iterations and faster feedback loops. VMs were a crucial enabler. Developers could finally spin up isolated development and testing environments, a luxury in the bare-metal world. For the first time, our infrastructure pets started to look a bit more like cattle—replaceable and manageable. Yet, a friction remained. While development cycles sped up, the operational side struggled to keep pace. Provisioning was still a sluggish process, and the "wall of confusion" between developers who wanted to move fast and operations teams who prioritized stability grew taller.
The final leap was the one that truly broke down that wall: the rise of Containers. This wasn't just an infrastructure evolution; it was the catalyst for a cultural revolution: DevOps. Containers provided the ultimate abstraction—a lightweight, immutable package containing an application and all its dependencies. This solved the "it works on my machine" problem and created a consistent artifact that could move from a developer's laptop to production without change. The architectural pattern of microservices flourished, allowing large applications to be decomposed into small, independently deployable services.
This fusion of containers, microservices, and Agile thinking created an environment of unprecedented velocity. But it also created an orchestration crisis. How could operations teams possibly manage the lifecycle of thousands of ephemeral containers, deploying hundreds of times per day? The very success of the DevOps movement—its emphasis on speed, automation, and shared responsibility—created an overwhelming technical challenge. The tools of the VM era were simply not equipped for this new, dynamic reality.
This is the chapter where our protagonist enters the stage: Kubernetes. Born within the walls of Google as "Project Borg" and forged by over a decade of experience running containers at planetary scale, Kubernetes wasn't just another tool; it was the answer to this crisis. It provided the framework, the architecture, and the philosophy for building and managing these sprawling digital cities. Let's delve into the blueprint of this metropolis.
The Journey to Orchestration
The evolution of infrastructure was driven by changing software development paradigms.
Bare Metal & Waterfall
Servers were unique, handcrafted "pets." The rigid, sequential Waterfall methodology mirrored this, with monolithic applications deployed infrequently in high-stakes events.
Virtual Machines & Agile
Virtualization enabled isolated environments, making servers more like replaceable "cattle." This supported the iterative cycles of Agile development, but a gap between Dev and Ops remained.
Containers & DevOps
Lightweight containers created portable artifacts, fueling the DevOps culture of speed and shared responsibility. This velocity created a new challenge: managing container fleets at scale.
Efficiency Gains Visualized
One of the key drivers for container adoption is resource efficiency. This chart illustrates the typical overhead associated with each paradigm, highlighting why containers enable much higher density.
The Kubernetes Revolution: Reshaping Modern Software Development
Since its open-source release in 2014, Kubernetes has transcended its origins as Google's internal orchestration tool to become the de facto standard for cloud-native application deployment. Its impact on the software industry cannot be overstated—it fundamentally changed how we think about infrastructure, application architecture, and the relationship between development and operations teams.
The adoption of Kubernetes marked a paradigm shift from infrastructure-centric to application-centric thinking. Before Kubernetes, operations teams spent countless hours managing servers, configuring load balancers, and manually orchestrating deployments. Kubernetes abstracted away the underlying infrastructure, allowing developers to declare what they wanted ("run 5 replicas of this container") rather than how to achieve it ("provision these VMs, configure this load balancer, set up these health checks").
This declarative approach became the foundation for GitOps and modern Infrastructure as Code practices. Engineering teams could now version control their entire infrastructure alongside their application code, enabling true continuous deployment at scale. The infamous "works on my machine" problem became a relic of the past as containers and Kubernetes ensured consistency from development through production.
Perhaps most significantly, Kubernetes democratized access to enterprise-grade infrastructure capabilities. Features that were once exclusive to tech giants—auto-scaling, self-healing systems, zero-downtime deployments, and multi-cloud portability—became accessible to startups and enterprises alike. This leveling of the playing field accelerated innovation across the industry and enabled the explosive growth of cloud-native ecosystems.
Today, Kubernetes powers everything from Fortune 500 enterprises to bleeding-edge startups, from on-premises data centers to all major cloud providers. It has spawned an entire ecosystem of complementary technologies—service meshes, serverless platforms, GitOps tools, and observability solutions—all built on the foundation that Kubernetes provides. Understanding its architecture isn't just about learning a tool; it's about understanding the operating system of modern cloud computing.
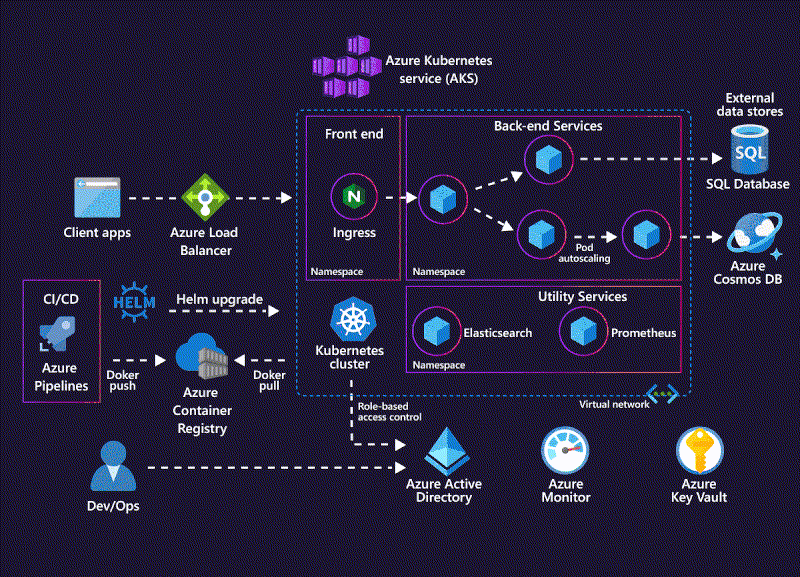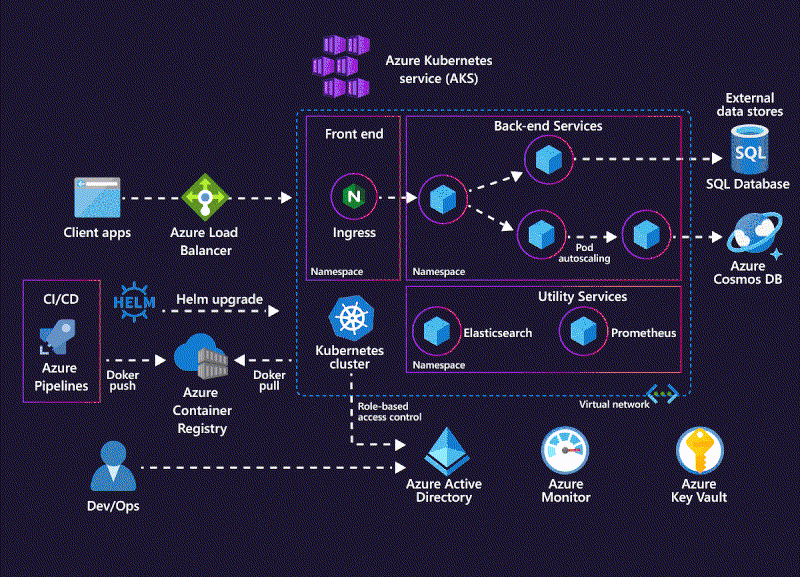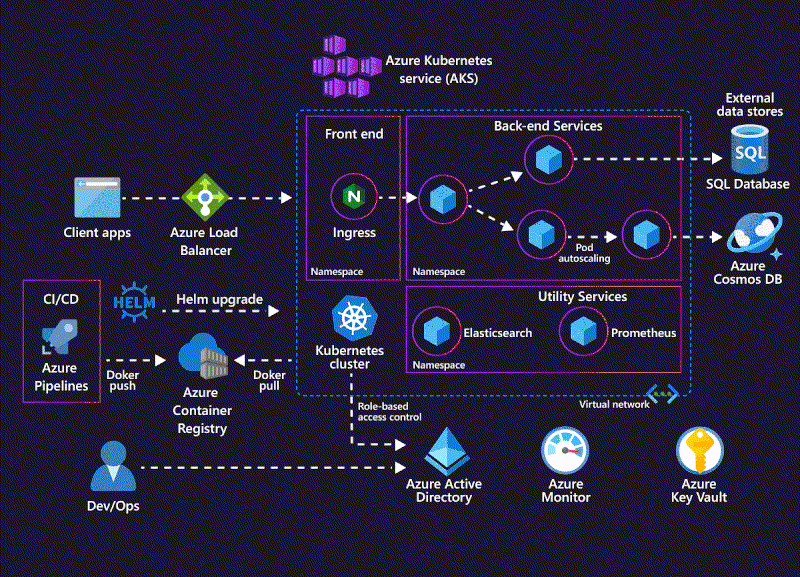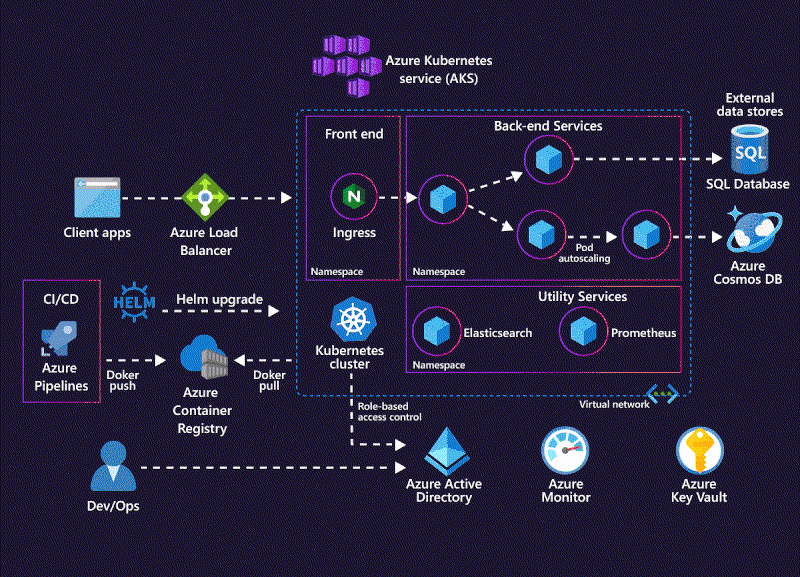
Kubernetes dynamically managing containerized workloads across a cluster
The Mastermind: The Control Plane
At the heart of every Kubernetes cluster lies the Control Plane, the collective consciousness and administrative brain of the system. It maintains the desired state of the cluster and makes global decisions based on that state. For high availability, these components are typically replicated across multiple "master" nodes.
kube-apiserver
The API server is the horizontally-scalable nerve center of the Control Plane. Every interaction with the cluster's state, whether from a user running kubectl, a script, or another cluster component, goes through this single front door. Its request pipeline is a critical piece of the architecture, performing three key steps:
- Authentication & Authorization: It first verifies who is making the request (AuthN) using strategies like client certificates, bearer tokens, or OIDC. It then determines if they have permission to perform the action (AuthZ), typically via the Role-Based Access Control (RBAC) system.
- Admission Control: Before persisting an object to etcd, the request passes through a series of admission controllers. Mutating controllers can modify the object (e.g., to automatically inject a sidecar container), and Validating controllers can reject it entirely if it violates policy (e.g., a Podwithout resource limits).
- Validation & etcd Persistence: Finally, it validates the object against the schema and, if successful, writes it to etcd.
The API server is the only component that directly talks to etcd, centralizing and securing access to the cluster's single source of truth.
etcd
Pronounced "et-see-dee," this is the cluster's consistent and highly-available key-value store. Built on the Raft consensus algorithm, etcd ensures that all master nodes have a consistent view of the cluster's state. It is highly sensitive to I/O latency, making fast SSDs a necessity.
Practical Implication: The entire state of your cluster lives here—every Deployment, Secret, and Pod definition. Losing etcd data means losing your cluster's state, making regular backups an absolute operational imperative.
kube-scheduler
This component is the master logistician, assigning newly created Pods to Nodes in a two-phase process:
- Filtering (Predicates): The scheduler first finds a set of feasible Nodes by running a series of checks. For instance, does the Node have enough available resources (PodFitsResources)? Is a port the Pod needs already in use (PodFitsHostPorts)? Does the Node satisfy the Pod's nodeSelector or affinity rules? Any Node that fails a check is eliminated.
- Scoring (Priorities): It then ranks the remaining feasible Nodes by applying a set of priority functions. For example, it might prefer Nodes that already have the required container image (ImageLocalityPriority) or those with the fewest allocated resources (LeastRequestedPriority). The Node with the highest score wins.
Practical Implication: Developers and operators can directly influence this process using taints (on Nodes) and tolerations (on Pods) to repel Pods, or using node/pod affinity and anti-affinity to attract or repel them from each other, enabling sophisticated workload placement strategies.
kube-controller-manager
This is a single binary that runs multiple distinct controller processes, each operating on a simple yet powerful reconciliation loop principle: Observe → Diff → Act. Each controller watches a specific resource. When it observes that the current state (reality) doesn't match the desired state (from etcd), it acts to reconcile the difference.
Examples include the Deployment controller (manages ReplicaSets to orchestrate rolling updates), the StatefulSetcontroller (provides stable identities for stateful apps), and the Node controller (responsible for noticing when nodes go down). This continuous reconciliation is the engine behind Kubernetes' self-healing capabilities.
The Kubernetes Metropolis
Explore the core architecture of a Kubernetes cluster. Click on any component in the diagram below to see a detailed explanation of its role and its practical implications for developers and operators.
Component Details
The Workforce: The Worker Nodes
If the Control Plane is the brain, the Worker Nodes are the brawn. These are the machines where your actual applications run. Each node runs a few critical components that connect it to the Control Plane.
kubelet
The primary agent on each node. The kubelet receives Pod specifications from the API server and brings them to life. It's responsible for:
- Instructing the container runtime (via the Container Runtime Interface - CRI) to pull images and run the containers.
- Managing storage for the Pod by mounting volumes (via the Container Storage Interface - CSI).
- Configuring networking for the Pod by interacting with the network plugin (via the Container Network Interface - CNI).
- Continuously reporting the status of the node and its Pods back to the API server.
Practical Implication: The kubelet also runs probes against your containers. A failing liveness probe tells the kubelet to restart the container. A failing readiness probe tells it the container isn't ready for traffic, causing it to be removed from Service endpoints, which is crucial for zero-downtime deployments.
kube-proxy
This is a network proxy that runs on each node and makes the Kubernetes Service abstraction work. It watches the API server for new Services and Endpoints (the list of Pods backing a Service) and updates the network rules on the node to route traffic accordingly. It can operate in several modes, with IPVS(IP Virtual Server) being preferred for large-scale clusters over the older iptables mode due to its superior performance for load balancing.
Container Runtime
This is the engine that runs containers. Thanks to the CRI abstraction, Kubernetes can work with any compliant runtime. While Docker was the pioneer, the ecosystem has shifted towards more lightweight runtimes like containerd and CRI-O, which are purpose-built for the orchestration needs of Kubernetes without the extra overhead of the full Docker daemon.
The Reconciliation Loop in Action
Kubernetes operates on a declarative model. You tell it the desired state, and its controllers work to make it a reality. This animation shows the simplified flow of a request, from user command to running pod.
The Architectural Genius for DevOps
Kubernetes' architecture is not just a technical marvel; it's the ultimate DevOps catalyst. It provides the robust, automated platform needed to support the velocity of modern development.
The API-centric, declarative nature is the bedrock of Infrastructure as Code (IaC) and GitOps. We declare the final state in YAML, commit it to Git, and let automation and the controller-driven reconciliation loops handle the rest. This creates a single source of truth and an auditable, repeatable process for managing applications. The Service object provides a stable IP address and DNS name for a volatile group of Pods—a simple abstraction that is profoundly powerful. It decouples consumers from producers, allowing Deployments to execute sophisticated rolling update strategies.
The system is built for elasticity. A Horizontal Pod Autoscaler (HPA) can automatically adjust the number of Pods in a Deployment based on observed metrics like CPU utilization. For even greater scale, the Cluster Autoscaler can provision or de-provision entire Worker Nodes from the underlying cloud provider based on the aggregate resource pressure of pending Pods. ConfigMaps and Secrets allow you to decouple configuration and sensitive data from your container images, adhering to the DevOps best practice of building a single, portable artifact that can be promoted across different environments with different configurations.
Kubernetes architecture is the fulfillment of the journey that began with those monolithic giants. It is a dynamic, living system designed for the ephemeral, fast-paced world of microservices. The saga is far from over, with new chapters being written by service meshes, serverless frameworks, and the Operator pattern, but Kubernetes has undeniably defined the operating system for the cloud.
The DevOps Catalyst
Kubernetes' architecture enables and accelerates modern DevOps practices. These key features directly translate into operational excellence and development velocity.
Declarative Model & GitOps
The API-centric, declarative nature is the bedrock of GitOps. We declare the final state in YAML, commit it to Git, and let the controller-driven reconciliation loops handle the rest, creating an auditable, repeatable process.
Service Discovery & Resilient Updates
The Service object provides a stable endpoint for a volatile group of Pods. This decoupling enables sophisticated rolling updates, redirecting traffic to new pods seamlessly without any client-side changes or downtime.
Dynamic Scalability
The system is built for elasticity. A Horizontal Pod Autoscaler (HPA) can scale pods based on metrics, while the Cluster Autoscaler can provision or de-provision entire nodes from the cloud provider, ensuring resource efficiency.
Configuration & Secret Management
ConfigMaps and Secrets decouple configuration from container images. This allows a single, portable application artifact to be promoted across different environments (dev, staging, prod) with the appropriate configuration injected at runtime.
An interactive visualization of “The Architectural Saga of Kubernetes”
← Back to Articles